
LLM推理-PD分离
大约 3 分钟
为什么要做PD分离?
大模型推理过程,可以分为两个阶段,预填充阶段(prefill stage)和解码阶段(decode stage)。 预填充阶段是计算密集型,解码阶段为内存密集型,两个阶段分别具有不同的推理特性。 如果把两个阶段放在同一个计算设备上,会导致两阶段优化目标SLOs冲突,而且耦合了两个阶段的部署策略。
如果不做PD分离的话,因为Prefill的推理时间更长,所以会导致同一批次进行的Decode任务延迟很大(必需等待Prefill完成)。
Prefill 和 Decode两阶段
| 项目 | Prefill Stage | Decode Stage |
|---|---|---|
| 输入长度 | >1(通常是几十到几万) | =1 |
| past_kv 参数 | None 或空 | 非空(来自上一步) |
| 是否生成 KV Cache | 是(初始化) | 是(追加) |
| 是否并行 | 是 | 否(自回归) |
| 在代码中的标志 | 第一次 forward 调用 | 第二次及以后的 forward 调用 |
| 复杂度 | ||
| 主要资源消耗 | GPU计算单元FLOPs | 内存和通信带宽 |
| 工程优化 | Flash Attention | Paged Attention、内存压缩等,目的是降低KV Cache内存占用 |
Prefill
在实际的请求中,第一次推理时,整个prompt都是新的输入,所以一次性送入模型,最终获取第一个输出的Token,这个过程就是Prefill。
# 假设 prompt_tokens = [1061, 338, 2945, 0] # "What is AI?"
logits, kv_cache = model.forward(
input_ids=prompt_tokens, # ← 这就是 Prefill 的入口!
past_kv=None # 没有历史缓存
)
next_token = sample(logits[-1]) # 取最后一个位置的 logits 预测下一个 token
在这个调用中:
- 模型对所有 L 个 token 并行计算 attention。
- 生成每一层的 K、V,并保存为 kv_cache。
- 输出 logits 的最后一个位置用于预测第 L 个 token(即第一个生成的 token)。
关键特点:
- 计算密集:完整运行模型的前向传播,计算所有输入token的注意力。复杂度与输入长度平方相关
- 并行处理:输入的所有token可并行计算,充分利用GPU等硬件加速
Decode
在第一个token生成之后,每次只输入一个新的token,并附带之前的KV Cache
# 第一次 decode:生成第 L 个 token 后,继续生成第 L+1 个
input_id = next_token.unsqueeze(0) # shape: [1]
logits, kv_cache = model.forward(
input_ids=input_id, # ← 只传入一个 token!
past_kv=kv_cache # ← 复用之前 Prefill 生成的缓存
)
next_token = sample(logits[0]) # logits 只有一个位置
正因为两个过程,都是执行的同样的forward所以才有chunked prefill的优化空间
关键特点:
- 内存密集:依赖KV cache读取历史数据,性能受限于内存带宽
- 串行生成:每次只能生成一个token,严格的自回归过程
- 计算最新token的注意力,复杂度与序列长度线性相关,
PD分离架构
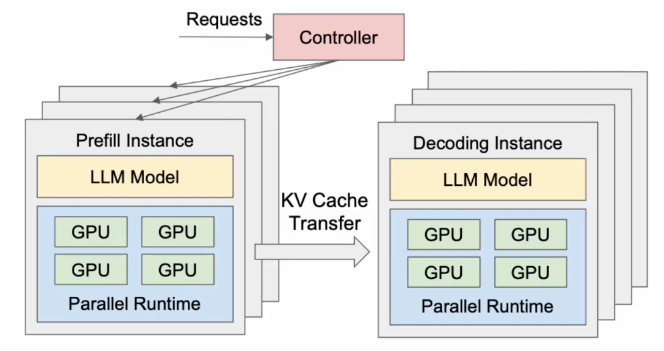
- 大模型的预填充阶段,部署在 Prefill Instance 节点上,专注于 Prefill 阶段的计算,得到KV 缓存。
- 大模型的推理阶段,部署在 Decode Instance 专注于 Decode 阶段自回归的生成任务。