
Transformer
大约 3 分钟
2017 年提出的 Transformer 完全摒弃了 RNN,仅依靠注意力机制来实现Seq2Seq,成为当前主流(如 BERT、GPT 等模型的基础)
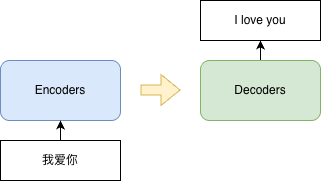
序列到序列(Seq2Seq)
Seq2Seq(Sequence-to-Sequence,序列到序列)是一种深度学习模型架构,主要用于将一个输入序列转换为另一个输出序列。它最初被广泛应用于机器翻译任务(例如将英文句子翻译成中文)。主要由两个部分组成:
- 编码器(Encoder)
- 接收输入序列(如文本向量)
- 使用神经网络,将输入序列转换为语义信息,生成固定长度的上下文向量(context vector)
- 解码器(Decoder)
- 以解码器生成的上下文向量作为初始状态
- 逐步预测下一个输出元素
Transformer结构
Transformer由6 * Encoder和6 * Decoder组成
Encoder
- Input Embedding: 将输入经过分词工具拆分为最小的语义单位
Token,每个Token会被编码为512维的向量, 最终多个词组成N * 512的稠密向量, 也就是Input Embedding。 - Positional Encoding:
Input Embedding是同时输入模型的,所以需要加入位置编码来表示词的相对顺序, 也就是Positional Encoding。这里原文是用的正弦/余弦函数,其他变种也有使用模型的。
每个Encoder内部,使用ResNet的思想,添加了Add & Norm连接。主体结构由Feed-Forward、Multi-Head Attention组成
- Feed-Forward: Transformer的Attention缺乏非线形的能力,这里引入FFN并使用ReLU增强拟合能力。
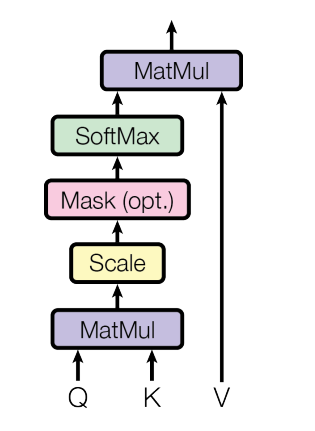
- Scaled Dot-Product Attention: 计算
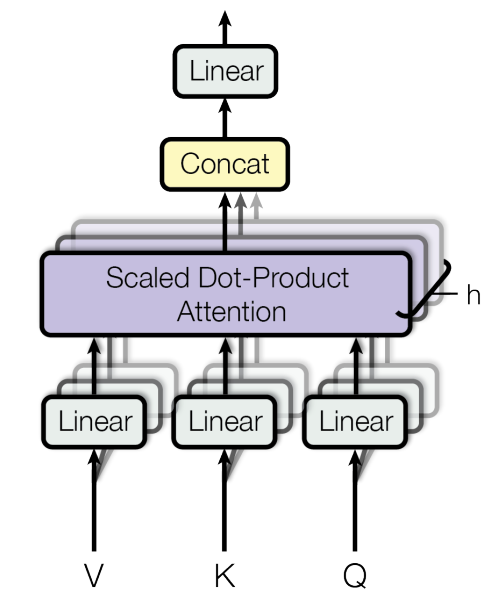
- Muti-Head Attention(Self-Attention): 多头注意力让不同的头关注不同的区间的向量,从而增强模型对输入序列中不同位置、不同语义关系的建模能力。
- Q: 查询向量,当前
Token关注什么 - K: 键向量,当前
Token能给其它Token提供什么信息 - V: 值向量,这个词实际包含的信息内容
- Q: 查询向量,当前
Decoder
Decoder的大部分结构类似Encoder,主要的不同在于:
- shifted right: 在训练阶段,将目标序列(target sequence)向右平移一个位置作为 Decoder 的输入。这是为了实现时间步上的对齐,从而正确计算Loss
- Masked Multi-Head Attention: 这里启用了Masked机制,并使用了两组注意力结构
- Masked Self-Attention: 为了让Decoder在生成第t个词时,不能看到未来词
- Cross-Attention: Q来自Decoder, K、V来自Encoder的最终输出,从而建立输出和输入之间的依赖关系。
当 Decoder 要生成 "爱"(对应英语 "love")时,Cross-Attention 会让它聚焦到 Encoder 中 "love" 对应的位置,从而实现跨语言对齐
[1] 词向量 | Transformer & Bert | 原理简介+代码简析