
词向量的演进过程
在NLP任务中,文本是没有办法直接参与数学计算的,因此首先要考将文本转换为数字,也就是文本向量。
分词器: 文本的拆分方法
分词器的目的是将连续的文本序列切分成有意义的、可供模型处理的基本单元(Token)。 这个“基本单元”的定义,随着计算能力、数据规模和任务需求的变化而演变。 其发展主线是:从追求人类可理解的“词”,转向追求模型高效处理的“子词”。
基于规则(字典)的分词
- 原理:维护一个词典。分词时,采用匹配策略在文本中查找最长能匹配的字符串。
- 经典算法:
- 正向/反向/双向最大匹配法:从左到右(或从右到左)扫描句子,每次尝试匹配当前位置开始的最长词典词。
- 例子:句子“我爱北京天安门”。
- 词典包含 {“我”, “爱”, “北京”, “天安门”, “天安”}。
- 正向最大匹配结果为 “我 / 爱 / 北京 / 天安门”(而不是“天安 / 门”)。
- 优点:简单、快速、对于词典内的词准确率高。
- 缺点:
- 未登录词(OOV)问题:无法识别词典外的新闻、专名、网络用语等。
- 歧义切分问题:如“羽毛球拍卖完了”,可切为“羽毛/球拍/卖完/了”或“羽毛球/拍卖/完/了”。
- 依赖高质量词典:不同领域需要定制词典,维护成本高。
基于统计的分词
- 原理:将分词视为一个序列标注问题。通过大量的已分词语料(训练数据)学习统计规律。
- 经典模型:
- N-gram语言模型:计算不同切分路径的联合概率,选择概率最高的路径。
- 隐马尔可夫模型:将“字”作为观测状态,“词位”作为隐藏状态进行学习。
- 条件随机场:更强大的序列标注模型,成为2010年代前后中文分词的主流技术。
- 优点:能一定程度上缓解未登录词(OOV)问题和歧义问题,数据驱动。
- 缺点:严重依赖标注语料的质量和规模,模型本身相对简单。
| 原理 | 优点 | 缺点 | |
|---|---|---|---|
| N-gram | 通过统计大量文本的字词组合概率,实现只看N个字,就能猜到下一个字 | 简单迅速 | 无法处理长距离依赖(N一般小于5) |
| 隐马尔可夫模型 | 通过词位标签(B-词首,M-词中,E-词尾,S-单字词),找到合理的分词。 比如,看到“天安门”,通过计算发现 天=B, 安=M, 门=E这个路径的概率,远高于天=S, 安=S, 门=S等其他路径 | 能考虑局部上下文 | 生成式模型,有马尔可夫性(当前标签只依赖前一个标签) |
| 条件随机场 | 判别式模型,在已知整个句子的情况下,直接找出最好的“标签序列”。每个特征函数都可以对整个句子的任何部分提出意见,最后投票决定最佳分词方案。 | 分词精度高,2010年前的SOTA | 需要设计特征模板,计算复杂度高。如今通常被深度学习模型(如BiLSTM-CRF、BERT)取代,但其全局归一化的思想被保留和继承 |
词向量 & 文本向量
离散表示时代
这个时代,使用one-hot的形式表示词,使用词袋法来表示词向量,可以解决 有没有、有多少 的问题
one-hot 编码
one-hot编码被用来当作词的表示方法。one-hot根据词语的数量N,生成长度为N的序列,只需要在当前词的位置标记为1即可。
- 缺点:
- 维度灾难:词数量大,导致维度过大
- 无法度量相似性:词之间的cos计算均为0
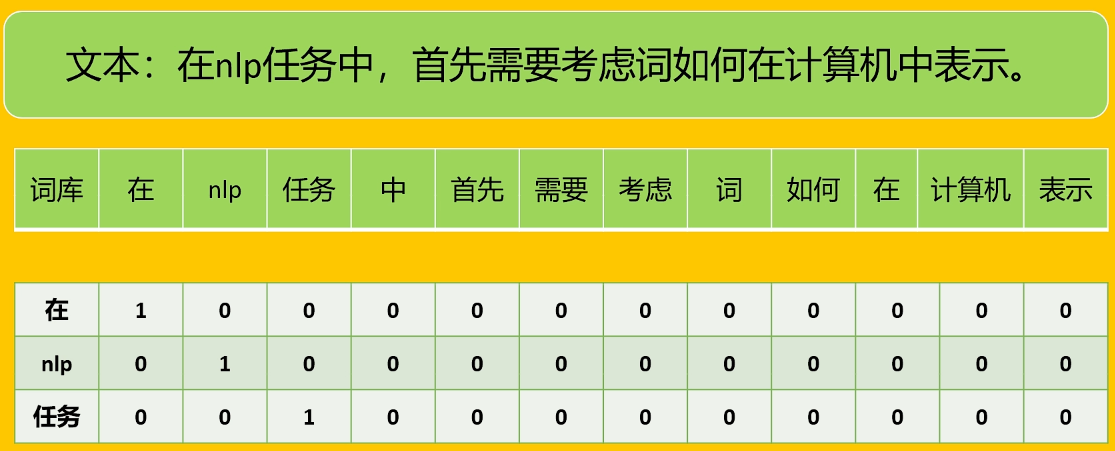
词袋法
词袋模型将文本视为一个“装满词的袋子”,忽略词序和语法。词袋法的构建过程,可以看作是对文档中所有词的one-hot向量进行“求和”或“叠加”。接收分词结果,直接构成词袋的“词汇表”。 每个文档都被表示为一个长向量,向量的每一维对应一个词,值可以是TF或TF-IDF权重。
- TF(词频):词在当前文档中出现的次数,越多可能越重要
- IDF(逆文档频率):也就是稀有度。在所有文档中都出现的词(比如“的”、“我们”),IDF值就低,说明它没区分度
- TF-IDF:也就是
TF * IDF,某个词当前文档的频率 * 整篇文档的稀有度
但是这样的话,对于大型文档会带来词汇表爆炸的问题,为此通常会进行停用词过滤和词干提取。
- 停用词过滤:筛选掉几乎每句话都有、但对理解内容毫无帮助的词,如功能词(的、了、在...)、标点、语气词(啊、呢)等
- 词干提取:把一个词不同的形态还原成基本形式(词干),让计算机知道它们表达的是一个意思,如英文(
running、runs -> run)、中文(北京市 -> 北京)
静态词向量时代
这个时代使用静态词向量表示词,使用池化、平均、编码器等手段表示文本,可以捕捉语义、语法信息。
词向量(Word Embedding)
词向量使用一个静态的词表 word -> vector[N]来提供向量查询,用有限的维度,表示无限的词语。这里的词表,是由模型训练而来的,经典的训练模型有Word2Vec、GloVe、FastText等
Word2Vec
原理: 假定文本中离得越近的词语相似度越高,通过浅层神经网络在大规模语料上训练,任务是根据上下文预测中心词(CBOW),或根据中心词预测上下文(skip-gram)。
- CBOW:用附近的词,预测中心词,类似完形填空,适合小数据集。
- skip-gram:用中心词,预测周围的词,类似造句,适合大数据集。 通过规定窗口的大小,来计算中心词和周围词共同出现的概率,来生成词向量。
缺点
- 没有考虑多义词:每个词语和词向量一一对应
- 无法处理复杂任务:基于局部的上下文,无法捕捉长距离的依赖关系
- 词向量是静态的:在不同的上下文中,词向量相同
文本向量
静态词向量为构建更好的文本向量提供了高质量的基石。早期生成文本向量的方法主要是对词向量进行简单聚合:
- 平均池化:将句子中所有词的Word2Vec向量取平均,作为句子向量。简单有效,但丢失了词序信息。
- 加权平均:如SIF算法,给高频词较低权重,以减少“的”、“是”等通用词的噪声。
- 专门训练的句子编码器:如InferSent、Universal Sentence Encoder,它们使用标注的句子对数据(如自然语言推理数据),训练一个编码器(如CNN、LSTM)将句子映射为向量,使得语义相似的句子在向量空间中靠近。这里的词向量通常是冻结的Word2Vec/GloVe。
动态词向量时代
这一时代,不再使用查表的方式获取词向量,而是实时的使用模型推理出词向量,可以解决一词多义的问题,典型的模型有ELMo、Bert。同时词向量和文本向量不再是两个分离的步骤,而是在同一个模型的前向传播过程中同时、动态地生成。
ELMo
原理: 使用双向LSTM,根据整个句子的上下文来生成词向量。上下文相关的词向量。它不再是查表,而是一个函数,输入是整个句子和词的位置,输出是该位置的词表示。
ELMo有两种主流的文本向量表示:
- 取顶层LSTM的最终隐藏状态
- 对于前向 LSTM:最后一个词(句尾)的隐藏状态编码了从句首到句尾的信息。
- 对于后向 LSTM:第一个词(句首)的隐藏状态编码了从句尾到句首的信息。
- 两个向量拼接之后就是整个句子的双向上下文信息。
- 对所有词的ELMo向量做池化:因为ELMo的设计初衷就是提供词向量表示
Bert
原理: 基于自注意力机制,使用Transformer编码器,通过掩码语言模型和下一句预测任务进行预训练。
创新点:
- 深度双向上下文:彻底捕捉词与词之间所有方向的依赖。
- 任务一体化:预训练过程同时学习了词、句子甚至句间关系的表示。
- 微调范式:BERT本身作为一个可微分的“文本编码器”,可以接入各种下游任务进行端到端微调,无需再设计独立的文本向量生成模块。
Bert有两种主流的文本向量表示:
- 取
[CLS]标记的最终层输出- Bert在训练时,会在每个输入序列的前面添加
[CLS]标记,例如"I love NLP的实际输入是[CLS], I, love, NLP - 为什么
[CLS]可以起作用?Bert的预训练任务之一是下一句预测(Next Sentence Prediction, NSP),模型判断两个句子是否连续的一句就是[CLS]位置的输出向量。所以[CLS]就隐藏了整句话的语义。
- Bert在训练时,会在每个输入序列的前面添加
- 对所有
Token的输出做池化- 有些研究发现,简单平均所有词的向量,反而在某些任务(如语义检索)上效果更好。
- 特别是在 没有 NSP 任务的模型(如 DistilBERT、RoBERTa)中,池化更可靠。
大模型时代
大模型时代已经不再有单独的词向量和文本向量,将一切皆向量的趋势进一步推进(不仅仅是词、文本,多模态中的图片、音频等也被嵌入为向量)。这个时代下,有BGE等专门的嵌入模型,也有GPT等通用大语言模型。
BGE
BGE模型中,向量是最终产品,通常用于RAG系统中的文档检索。
LLM
LLM模型中,向量是中间状态,用于服务大模型内部的计算,度量性质相比BGE较差。但也可以通过专门的微调来适配向量生成任务,如Qwen-Embedding。