
Redis的高可用集群
大约 4 分钟
1. 主从
Redis的主从复制是指将 主节点(master) 的数据复制到 从节点(slave) 的过程,是高可用的基础,其作用主要包括:
- 数据冗余:是除了持久化之外的另一种冗余方式
- 故障恢复:主节点故障时,从节点可提供服务
- 负载均衡:可以读写分离,主节点负责写,数据由主同步给从,主、从节点负责读
1.1 主从复制原理
Redis起初只有全量复制这一种方式,2.8版本后新增了增量复制方式
1.1.1 全量复制
通过relicaof xxx:xxx命令来让多个Redis之间形成主从关系,建立主从关系后,按照三阶段进行复制:
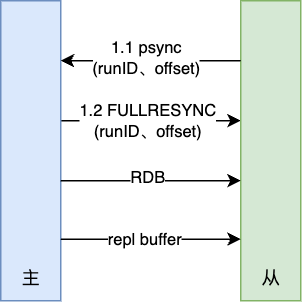
- 首先,主从建立了连接并协商同步,由从节点发起
psync并携带runID(主节点ID,启动时随机生成,初始-1)和offset(主节点的同步位点,初始?),主节点确认回复后即可以同步 - 其次,主节点执行
bgsave生成将RDB快照并发送给从节点,从节点接收RDB后清空当前的库,并加载RDB;此时主节点产生的新数据将存储在replication buffer中 - 最后,主节点将过程中产生的
replication buffer再发送给从节点
1.1.2 增量复制
若主从在命令传播时出现了网络波动,则需要重新进行全量复制,开销较大,因此出现了增量复制来解决这个问题。在主从断开之后,repl_backlog_buffer记录了主从的差异数据而避免重新的全量复制(断开时间过长仍需要全量同步),并在下一次恢复同步时通过replication buffer发送到从节点
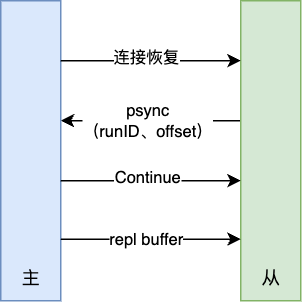
- 首先,主从之间进行连接的恢复
- 其次,从节点将之前的
runID和offset发送给主节点 - 最后,继续同步发送
replication buffer的内容
1.1.3 主从容易产生的问题
1. 延迟不一致问题
由于从节点的数据是由主节点异步复制的,所以难以避免存在延迟问题。常见的解决方法有:
- 优化网络速度,若存在延迟高的节点应让其停止服务
- 调节
slave-serve-stale-data,该参数控制着从节点在数据同步或失去主节点连接时的表现,如果设置为no则从节点只能响应info、slaveof等少数命令
2. 数据过期问题
Redis有两种删除策略:
- 惰性删除:不主动删除数据,当查找时判断过期再删除
- 定期删除:定期扫描并删除一次
而Redis的从节点不会主动删除数据 ,这一部分在3.2版本中进行了优化,如果数据已过期则不会返回结果
2. 哨兵
哨兵机制主要负责主节点的自动故障转移,具有以下功能:
- 监控:不断检查主、从节点的状态
- 自动故障转移:当主节点故障时,哨兵会让其他一个从节点变为主节点
- 配置提供:客户端可以通过哨兵获得主节点位置
- 通知:哨兵将主节点故障通知给客户端
2.1 哨兵集群
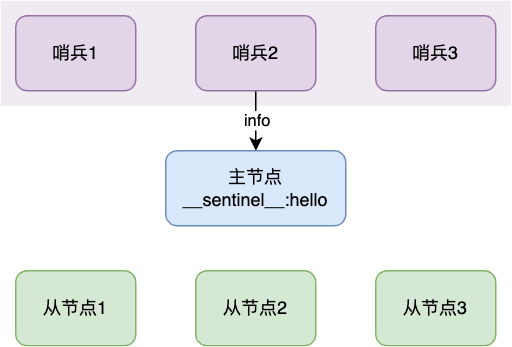
如图,哨兵集群的启动过程如下:
- 主节点连接:多个哨兵连接主节点
- 哨兵连接:多个哨兵订阅主节点的
__sentinel__:hello频道,以此获取相互的地址,进而建立通信 - 从节点连接:哨兵向主节点发送
info命令,主节点返回从节点的信息,进而与从节点建立连接
2.2 主节点
2.2.1 主节点下线判定
- 某个哨兵判断主节点下线后,因为未经验证,所以是**“主观下线”**
- 此时向其他哨兵发送
is-master-down-by-addr命令,其他哨兵对此进行投票 - 如果赞成数大于
quorum配置,则可以判断主节点**“客观下线”**
2.2.2 故障转移
- 选出哨兵领导:当主节点下线后,需要一个哨兵站出来完成故障的转移和通知,此时则需要一个选举机制,即Raft算法。此时依旧是哨兵们相互投票,如果有哨兵的票数>哨兵总数的一半则成为领导者。
- 选择主库
- 首先过滤掉不健康和网络差的节点
- 根据人工配置
slave-priority从节点的优先级来选择 - 选择复制偏移量最大的(数据最新最完整)
- 故障转移
- 被选中的从节点脱离原主节点,并成为新的主节点
- 其他从节点连接至新的主节点
- 哨兵领导通知客户端节点的改变情况
- 原主节点变成从节点