
Redis的底层数据结构
1. 介绍
Redis包含以下底层数据结构:
- 简单动态字符串SDS
- 压缩列表ZipList
- 快表QuickList
- 字典/哈希表Dict
- 整数集IntSet
- 跳表ZSkipList
1.1 简单动态字符串SDS
Redis由C语言实现,但在String上并没有采用C语言的字符串,而是自己实现了简单动态字符串(simple dynamic string,SDS),SDS由头部、数据(buf)和\0结尾组成:
- 头部分别由
uint8、16、32、64四种大小的len(buf的已用长度)和alloc(buf的实际分配长度),以及一个unsigned char的flag(低三位代表头部的类型)组成 char buf[]负责存储数据\0用来当作结尾

SDS主要是以头部的len和alloc来达到O(1)的字符串长度读取。在字符串修改的情况下,这对于预分配空间(改长)和惰性空间释放(改短)十分有用
- 目前的预分配规则是如果字符串小于1M则分配双倍的内存,如果大于1M则多分配1M,防止频繁扩容
1.2 压缩列表ZipList
ZipList是一种特殊的双向链表,可以存储字符串(SDS)或整数(二进制):
- zllbytes:记录整个链表大小
- zltail:记录entry最后一个偏移量,用于定位尾部,完成pop等操作
- zllen:entry的数量,最大
2^16=65535,如果超过这个数字则需要遍历 - entry:实际的节点
- 存储字符串时:prevlen(前一个entry的大小)+encoding(当前的类型和大小)+entry-data(实际数据)
- 存储整数时:合并encoding和entry-data
- zlend:终止符

优点: ZipList相比数组,其各个节点的类型、大小可以变化,更节省内存
缺点: ZipList不预留空间,在每次写后都会进行内存分配
1.3 快表QuickList
QuickList是以ZipList为节点的双向链表,这样的实现方式可以让链表里的元素在更新时不需要再更新整个链表,而是更新一个ZipList节点的内存即可
1.4 字典/哈希表Dict
Redis中的Hash组成如下,其中size代表大小,sizemask用于计算索引值,used记录了已有节点的数量
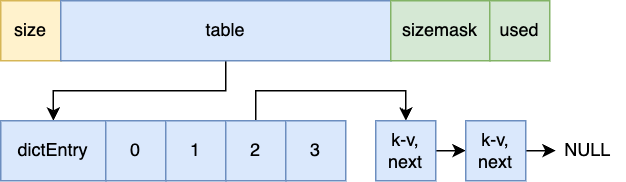
- 冲突:当Hash发生冲突时,采用链地址法,将next指向下一个相同的索引的节点
- 扩容/收缩:扩容/收缩一倍,重新建立哈希表,删除原哈希表
- 扩容机制:服务器没有执行BGSAVE时(RDB)负载因子(平均每个链表上的节点数)>=1;执行时负载因子>=5
1.5 整数集IntSet
整数集(IntSet)是集合类型的底层实现之一,当一个集合只包含整数值元素,并且这个集合的元素数量不多时,Redis 就会使用整数集合作为集合键的底层实现。
整数集的结构非常简单,由:
- encoding:编码方式
(INTSET_ENC_INT16, INTSET_ENC_INT32, INTSET_ENC_INT64) - length:存储的整数个数
- contents:数组,元素类型由encoding决定,各个项按照值的大小有序排列,且不重复
集合的升级、降级:
- 升级:如果往
INT16的集合插入32位的数据,则会先创建一个INT32的集合再把数据移动过去 - 降级:为了减少开销不会降级
1.6 跳表ZSkipList
有序列表ZSet使用了ZSkipList作为底层结构,是一种空间换时间的思想
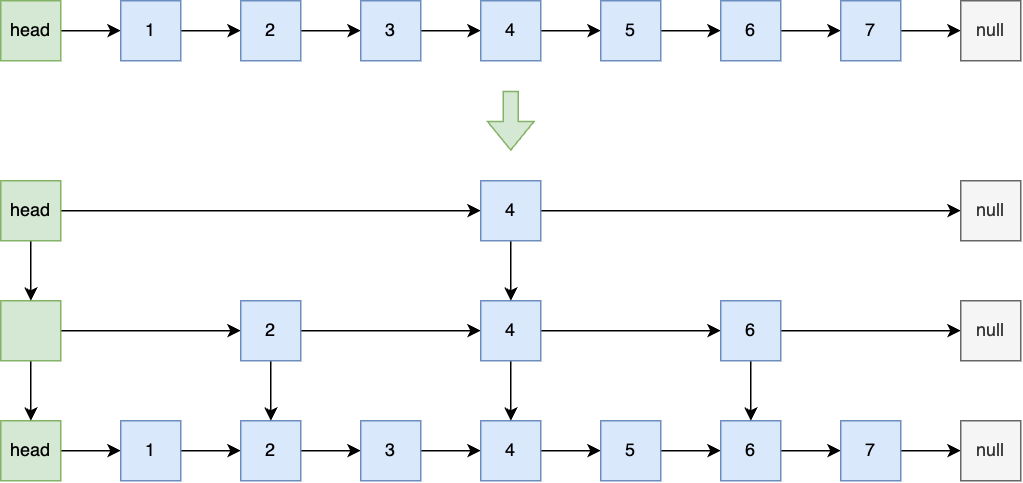
如图,在有序的情况下,普通链表想查找7需要一直访问它的next指针,进行7次遍历。 由于数据是有序的,所以可以使用类似二分的思想,减少遍历的次数,此时只需要访问3次(4->6->7)即可,这样可以将查找的速度优化为O(logN)
然而这样做的话,在删除和增加节点时会导致上下层的关系并不能继续保持2:1,比如说插入2.1、2.2、2.3 ...,此时必须调整整个跳表的结构,否则查询的速度就会退化到O(N)
为此,Redis引入了随机层数的方法,即对插入的节点赋予一个随机的层数(每层往下的概率都是50%,即L1-50%、L2-25%...),这样虽然查询的效率会略低一些,但缺解决了插入和删除的问题,跳表定义如下:
typedef struct zskiplistNode {
# 实际的值
sds ele;
# 分数,也就是排序的依据
double score;
# 上一节点
struct zskiplistNode *backward;
# 层级
struct zskiplistLevel {
# 下一个节点
struct zskiplistNode *forward;
# 距离下一节点的跨度
unsigned int span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
为什么不用各种平衡树实现呢?
- 各种平衡树对于插入、删除节点都需要进行重建或者局部重建,而跳表相对更加简单灵活
- 从内存占用上来说,skiplist比平衡树更灵活一些。一般来说,平衡树每个节点包含2个指针(分别指向左右子树),而skiplist每个节点包含的指针数目平均为1/(1-p),具体取决于参数p的大小。如果像Redis里的实现一样,取p=1/4,那么平均每个节点包含1.33个指针,比平衡树更有优势。查找单个key,skiplist和平衡树的时间复杂度都为O(log n),大体相当;而哈希表在保持较低的哈希值冲突概率的前提下,查找时间复杂度接近O(1),性能更高一些。所以我们平常使用的各种Map或dictionary结构,大都是基于哈希表实现的
- 从算法实现难度上来比较,skiplist比平衡树要简单得多