
FuserLab(AI发布、评估、观测平台)
Why Fuser
为什么在开源方案漫天飞的情况下选择自己做
- 开源项目没有绝对银弹,像 25 年比较火爆的 Dify、Coze,到了 26 年已经是智能体的天下了,热度明显降低
- AI Coding 崛起,产研成本大幅降低,想法落地的时间大幅缩减
Fuser 本身的意思是融合,即融合市面上的解决方案,取其精华。
背景
我是 25 年中,因为部门专门做 AI 的大姐姐走了,也算是临危受命,把我从集团抽回来负责 AI 相关的工作。
当时花了 1 周时间摸清了现状。整体是提供智能客服服务,Dify + vLLM 部署的 Qwen2.5-14B + xInference 部署的 BGE-M3 和 BGE-Rerank,本质上就是一个工作流(意图识别 + RAG)。实际上除了 Dify 的工作流,里面也掺杂了很多用 FastAPI 写的接口,用来弥补灵活性上的问题(比如当时 Dify 的问题分类器难用的要死)。
在她即将离职的最后一周,我提了要自己做编排层,放弃开源方案。当时的规划是先做知识库/工作流部分,外挂 Dify 的知识库,后续再把知识库切进来。
困境与转机
当时有一个困境——产能严重不足。在传统企业,要做一个平台或系统,需要走完整的产研立项流程,最起码需要产品来推动。没有 PRD 就没有后续的 UI、前后端研发力量的配合。
但实际上,传统公司的产品对 AI 相关的东西确实不熟,一方面不想无端生事,一方面确实不懂,所以就不了了之。
就这样,虽然当时也开始了自研工作,但并不是冲着平台的目标去的,只是用 Python 搓了工作流和智能体的编排。
直到 26 年初,随着半年的积累,加上 AI 工具的成熟,发现已经可以完成产品的闭环了:
- 产品:研发本身就是 AI 产品的深度用户,用豆包、Trae 帮忙梳理需求,做开源项目的拆解对比
- UI:Figma/V0 帮忙生成,导出之后给 Trae 实现
- 前端:Vue,本身具备一些基础
- 后端:Python,恰巧也具备一些基础
于是在跌跌撞撞中,项目就此起步。
核心定位:全链路闭环
想做好 Agent,必须要有生命周期管理,只要功能不要质量不可取。
Fuser 要做的是一个全链路闭环的 AI 集成中台,而不仅仅是 AI 应用的编排工具。对比市面上的方案:
| 维度 | Fuser | Dify | LangChain/LangGraph | Coze / LangFuse |
|---|---|---|---|---|
| 定位 | 全链路闭环的 AI 集成中台 | 低代码 AI 应用构建平台 | AI 应用开发框架 | AI 追踪、评估、调测平台 |
| AI 应用构建 | 支持,集成 LangChain/LangGraph 框架 | UI 拖拽 | Coding | / |
| 追踪、评估、调测 | 支持 | / | / | 支持 |
| 上下文工程 | 支持,有自研、Dify、AI 公司等多种接入方式 | Dify 知识库 | / | / |
| 高并发/高可用 | 技术自主可控,支持扩展 | 开源,扩展难度大 | / | 开源,扩展难度大 |
选择自研的核心原因:
- 开源方案各有优劣、迭代受限、没有绝对银弹(半年过去 Dify 和 Coze 的热度已经明显下降)
- 开源方案商用困难,扩展性差
- AI Coding 时代,取其精华的成本大大降低
What Fuser
Fuser 是一个全链路闭环的 AI 集成中台,用于构建和部署定制化、高并发、高可用的 AI 应用。平台涵盖 AI 应用从开发、调试、发布、观测到评估的完整生命周期。
平台功能
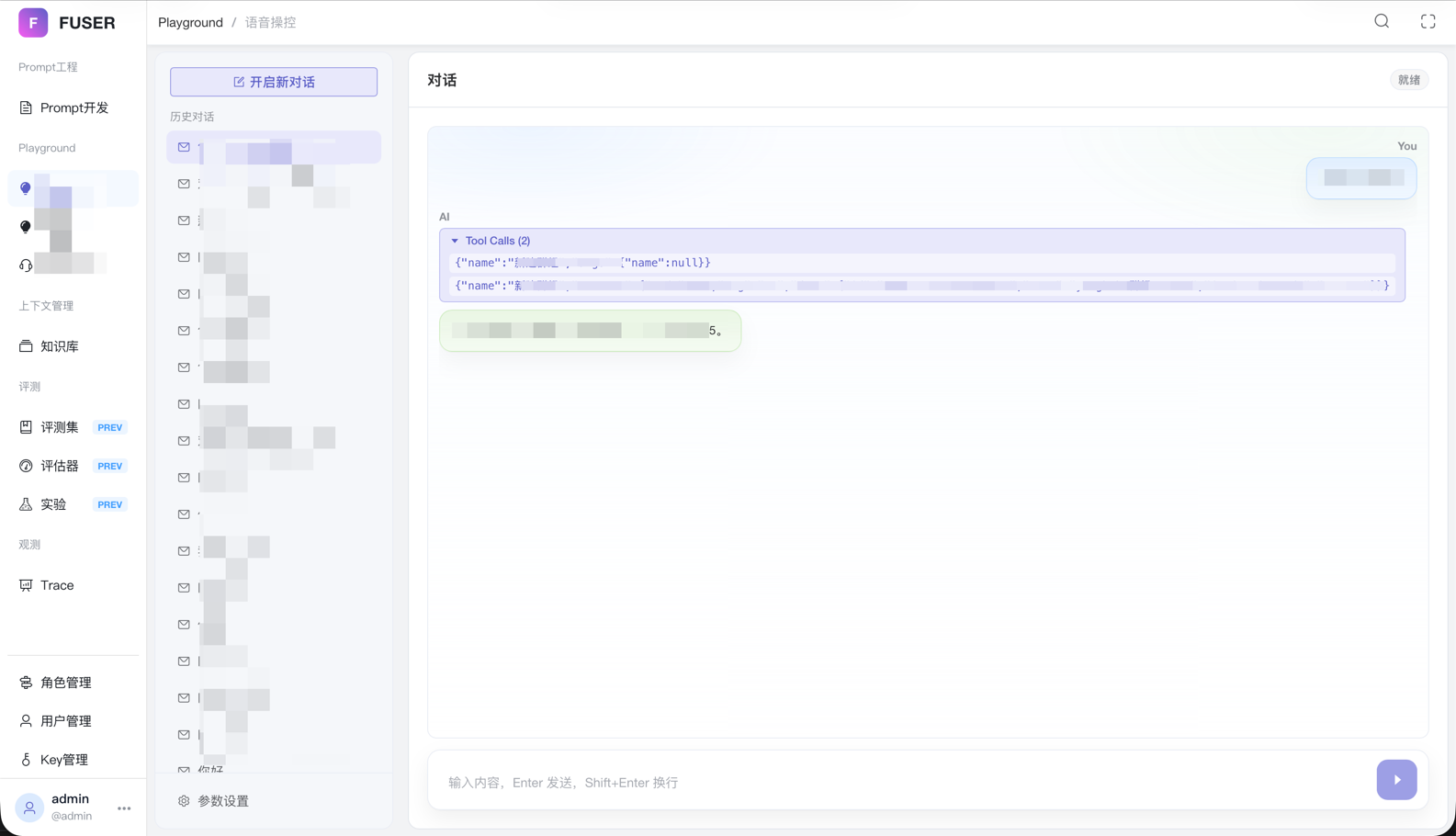
1. Playground
为什么做这个功能
在传统研发流程中,产品提了需求之后,需要等后端开发完成、部署到测试环境,产品和测试才能开始验证。这个过程中:
- 前后端联调等待时间长,一次联调动辄半天
- 产品的想法无法快速验证,调一个提示词也要走发版流程
- 普通产品/测试人员看不懂日志,无法自助调试
我们希望产品、测试可以不依赖后端开发,直接进行调试和验证,同时提供最详细的调用细节,让调试不再是研发的特权。
现在的效果
- 提供 SSE 流式对话界面,实时展示 AI 响应
- 产品和测试可以直接在 Playground 中验证新提示词、新模型,无需等待后端发版
- 已接入智能客服、语音操控、智能总结等多个业务场景
2. 发布模块(Prompt 管理 + 热更新)
为什么做这个功能
在业务落地过程中,最频繁的变更不是代码,而是提示词。
比如一些业务,运营经常需要调整 AI 的话术风格和语气,但每次调整都要:
- 研发修改提示词 → 提交代码 → 走发布流程 → 联合运维发版
- 单次发版耗时约 30 分钟,效率极低
- 而且发版有风险,运维不愿意频繁操作
一个月调整 10 次话术,就要发版 10 次,谁也不愿意这么折腾。提示词的变更不应该依赖代码发布。
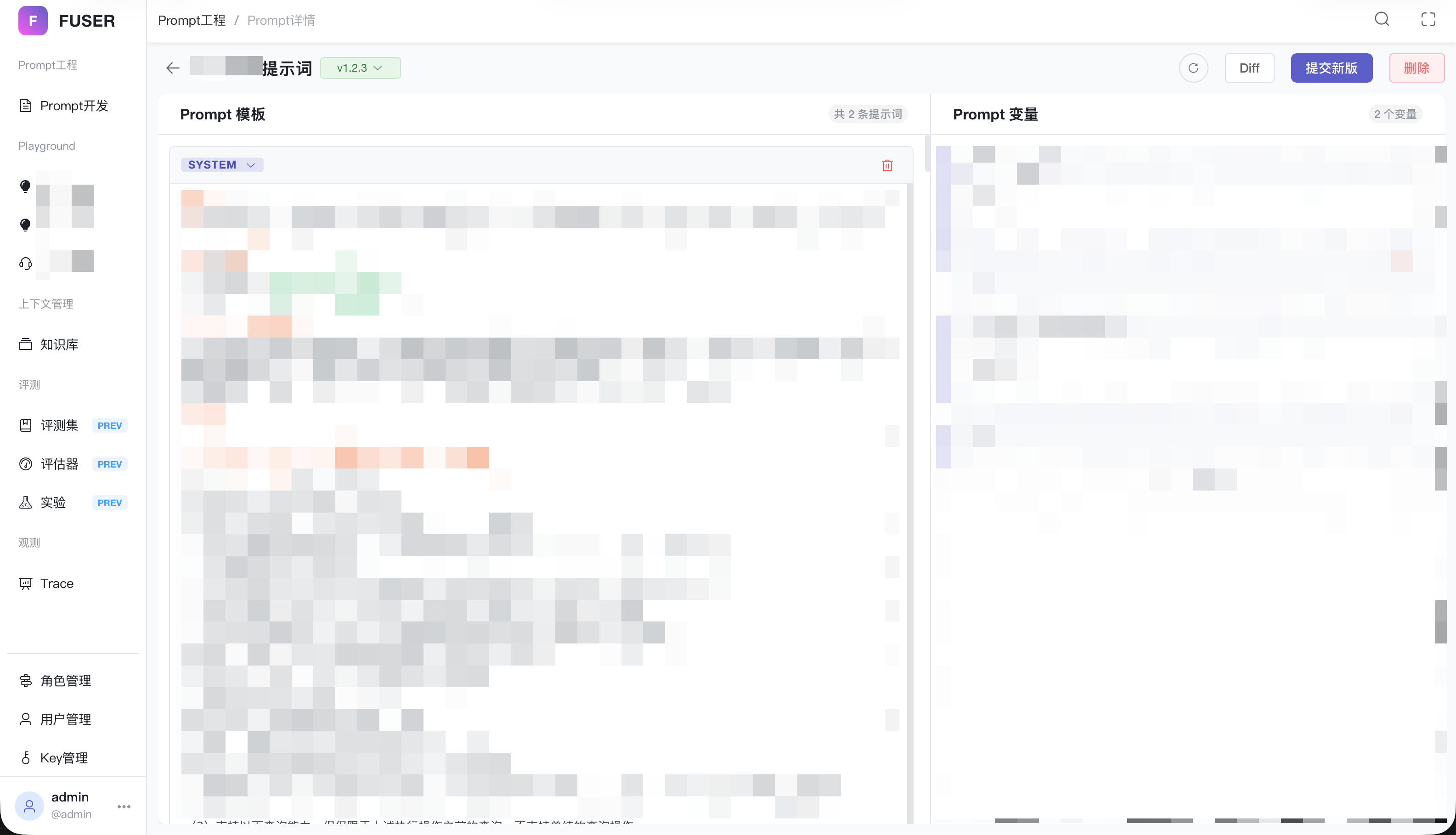
现在的效果
- Prompt 版本管理:所有 Agent 的提示词纳入平台统一管理,支持版本历史、版本对比(Diff)
- 热更新:修改提示词后秒级生效,无需重启服务、无需发版
- 变量管理:提示词中的可变部分(如业务参数、用户信息)通过变量注入,提示词模板与数据分离
- 产品需求从"等研发排期 + 发版"变成分钟级就绪
- Before:生产环境发版 30min 起步 → After:60s 自动刷新
3. 评估模块(LLM-as-a-Judge)
为什么做这个功能
Agent 开发中最头疼的问题:你怎么知道调了提示词之后,效果是变好了还是变差了?
传统的做法是:
- 拉几个样例人工看一下,感觉"差不多"就上线了
- 产品/测试无法提供规模化评测数据
- Agent 是一个黑盒,调了一个地方,可能另一个场景就崩了(回归问题)
- Bad Case 零散、无法统一收敛,纯靠人工回归验证
这就像改代码没有单元测试——你敢改吗?没有评测体系,Agent 迭代就是在裸奔。
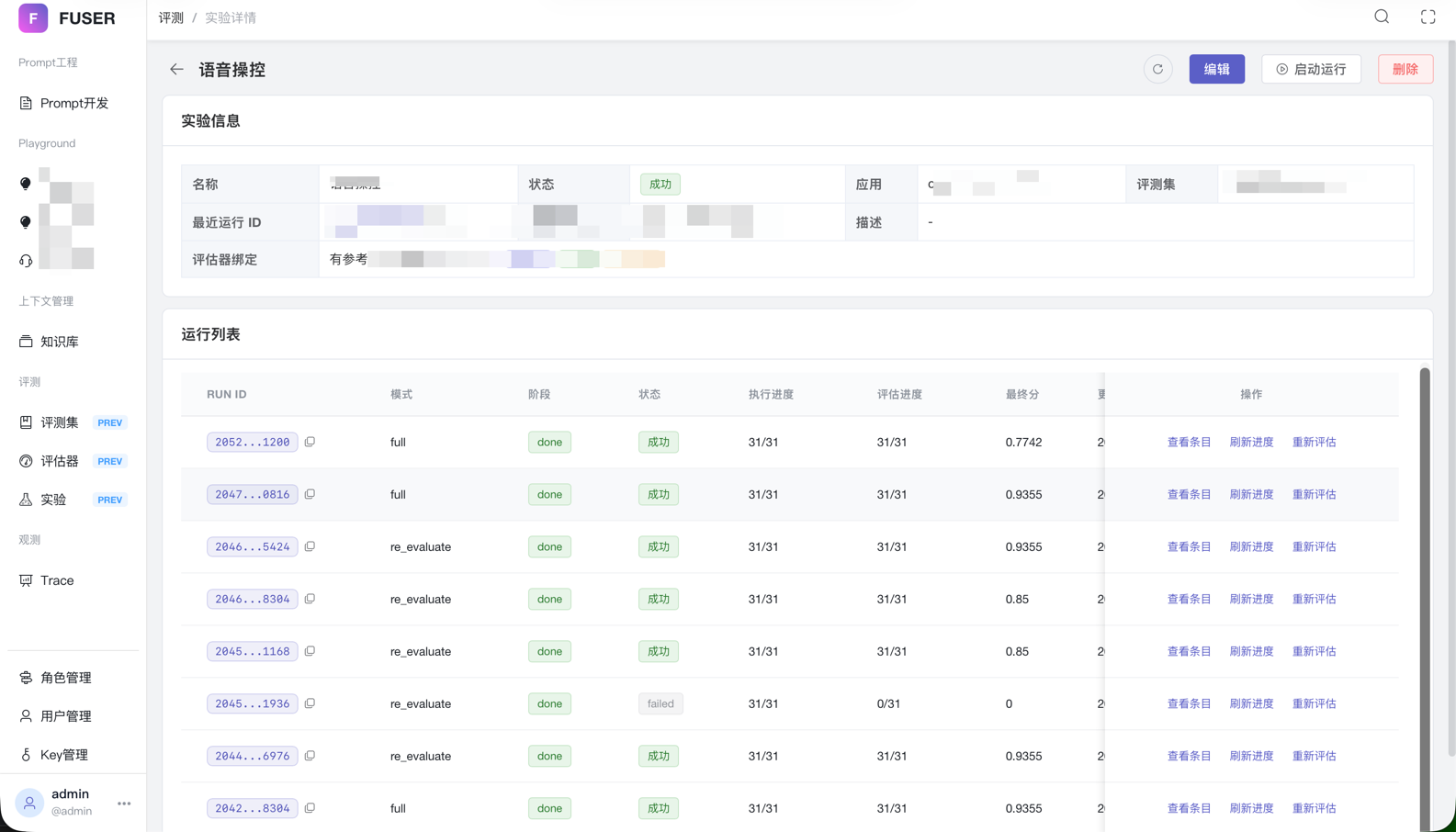
现在的效果
- 数据集管理:评测数据的统一管理,支持手动添加、批量导入、Excel 导入导出、版本管理
- 评估器管理:LLM-as-a-Judge,用 AI 评估 AI 的输出质量;支持有参考/无参考两种评估模式;支持对 message、tool 调用进行过滤评估
- 实验管理:支持异步、批量执行实验,多个评估器并行打分;支持实验对比,效果可量化、可视化
- Before:仅靠少量样本主观评估,效果好不好"凭感觉";Agent 调优顾此失彼
- After:规模化客观评估,多维度量化打分;Bad Case 沉淀为评测集,拒绝回归问题
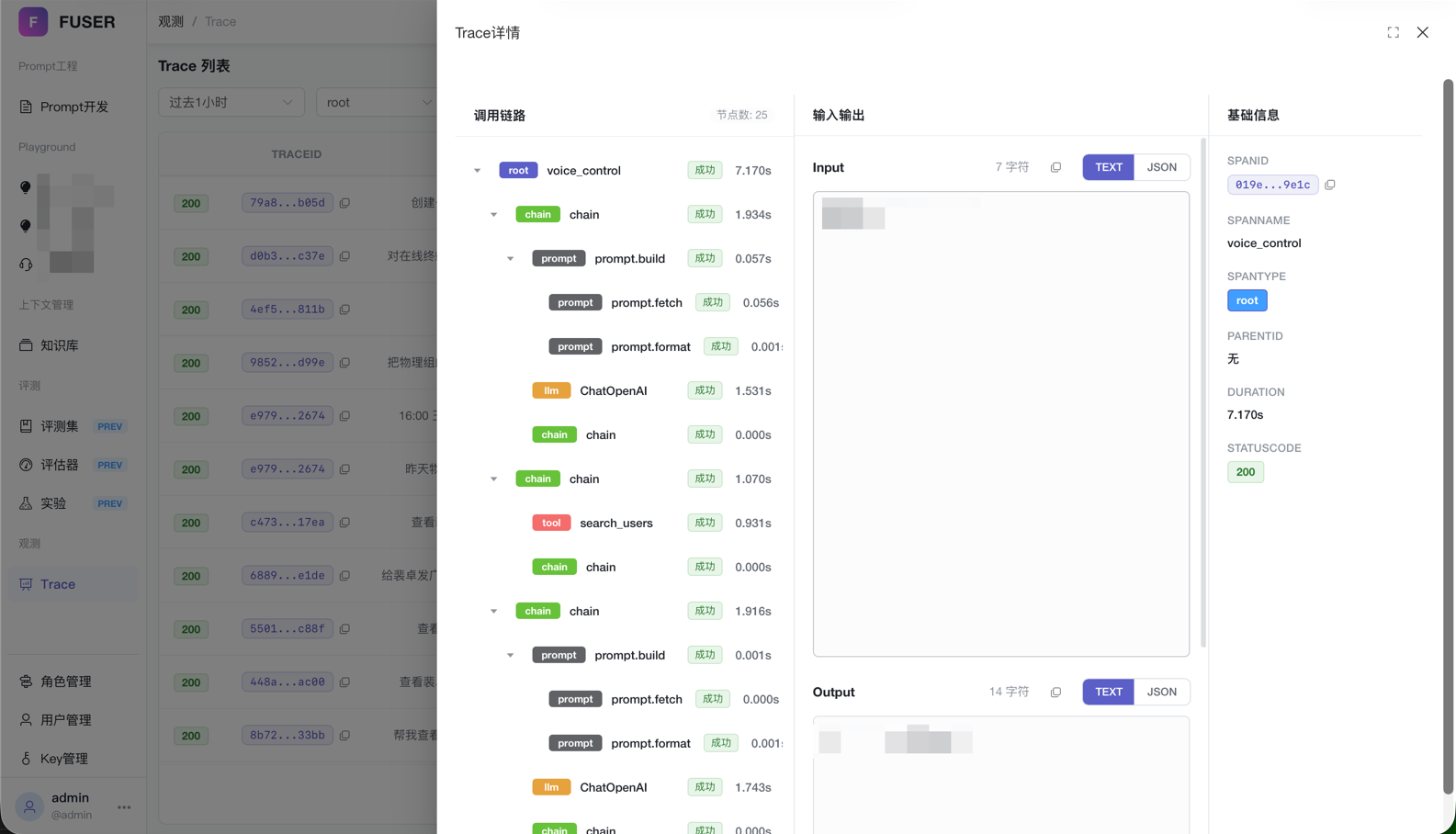
4. 观测模块(全链路追踪)
为什么做这个功能
Agent 上线后,线上出了问题怎么排查?
比如直播宝要求首字响应 < 3s,但用户反馈慢。传统做法是:
- 去服务器上翻日志,grep 关键词大海捞针
- 链路复杂(网关 → 意图识别 → RAG 检索 → LLM 调用 → 后处理),根本不知道卡在哪一环
- 没有统一的性能指标,无法定位瓶颈
Agent 的黑盒问题不仅体现在效果上,更体现在性能和稳定性上。没有可观测性,线上 Agent 就是在裸奔。
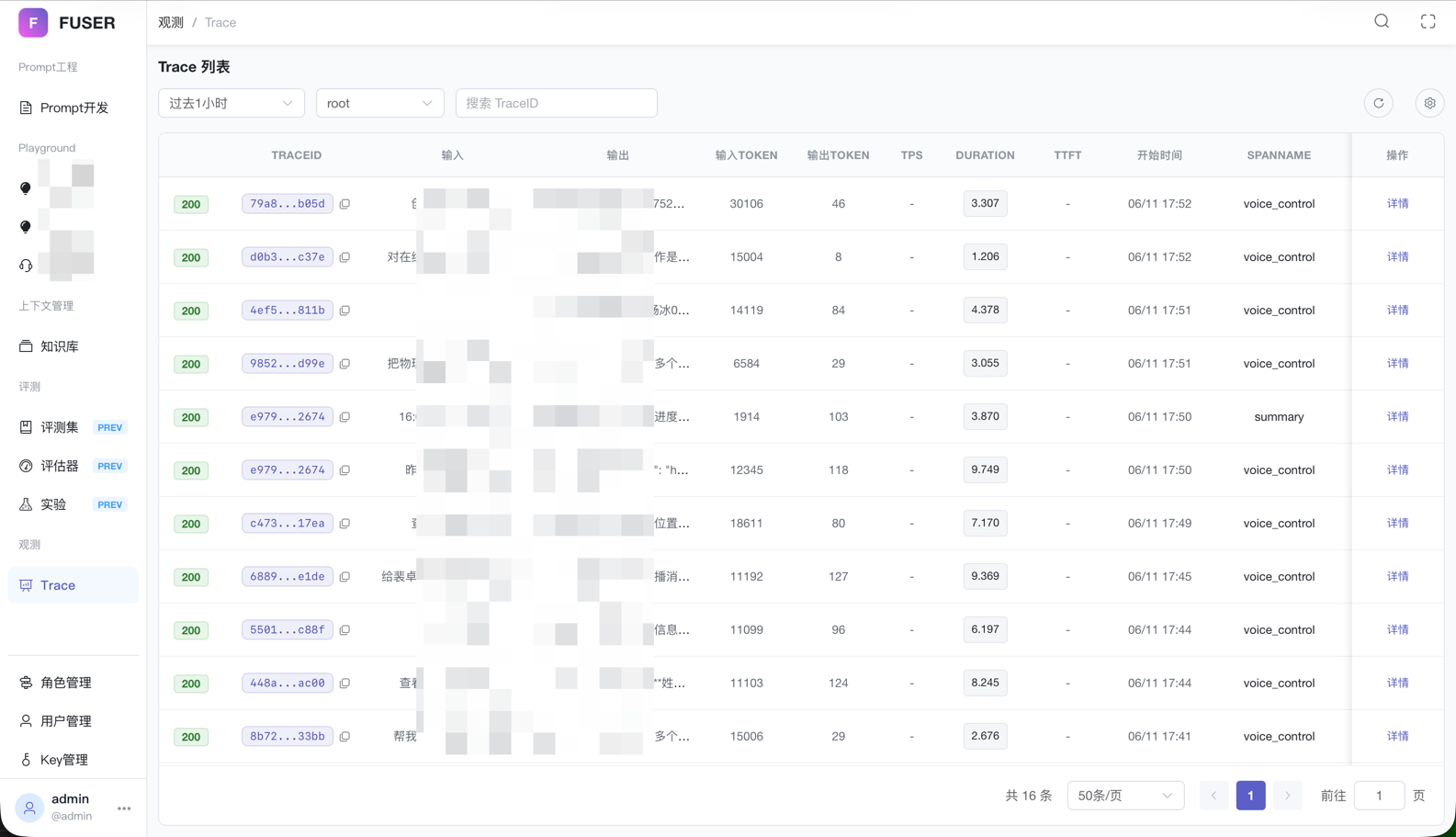
现在的效果
- Trace CallBack:Agent 运行时自动上报数据,无需业务代码侵入式修改
- 全链路可视化:按 trace_id 获取完整调用链路,支持 span 树形展开
- 核心性能指标:Tokens、TTFT(首字时间)、Duration、TPS 等一目了然
- 详情查看:每个 span 的输入/输出完整展示,支持树形结构和 JSON 视图
- Before:链路黑盒,耗时环节无法定位,在茫茫日志里大海捞针
- After:全链路可视化,问题分钟级定位
5. 知识库(上下文工程)
为什么做这个功能
RAG 是 AI 应用中最基础的组件,但之前的方案存在明显问题:
- Dify 的知识库功能封闭,无法灵活定制检索策略
- 不同业务需要不同的切片策略、检索参数,但 Dify 只提供有限的配置
- 自研的知识库后续可以与其他模块(评估、观测)联动,形成数据飞轮
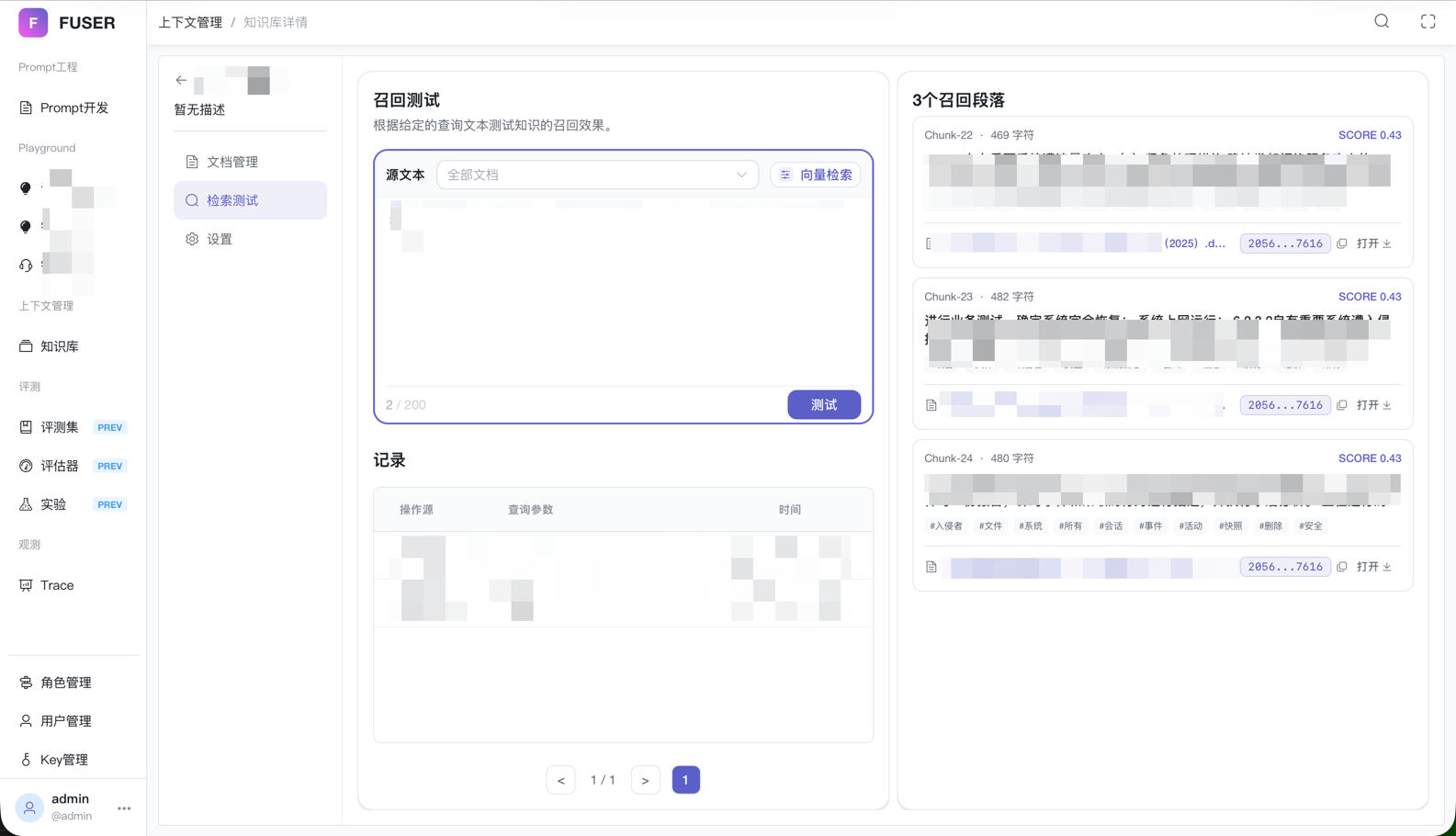
我们希望知识库不仅要能用,还要可观测、可评估——索引了多少文档、检索命中率如何、召回质量怎么样,这些都应该是透明的。
现在的效果
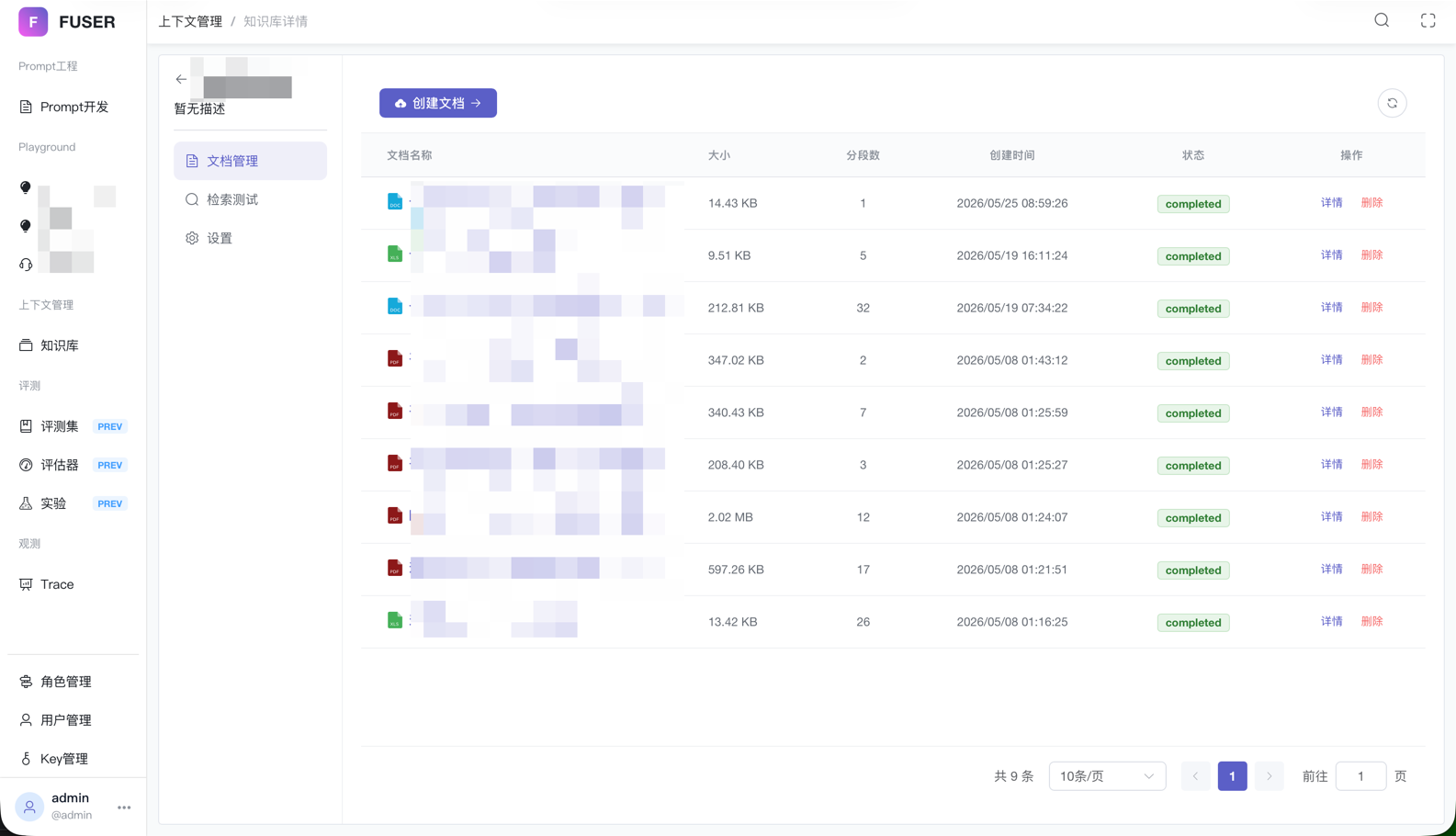
- 标准三级结构:知识库 → 文档 → 段落
- 文档管理:支持上传、索引、索引状态追踪、索引预估
- 检索测试:在知识库详情页内置检索测试面板,输入 query 即可实时查看检索结果
- 段落管理:支持段落级别的增删改查、批量删除
- 知识库与其他模块打通:Agent 编排中可直接引用知识库;后续可与观测联动,分析检索命中率等指标
下一步计划
- 数据飞轮:评估数据集 → 评估达标 → Agent 上线 → 线上质量抽查 → Bad Case → 沉淀回评估数据集,形成闭环
- 在线评估:实时抽检线上的质量问题
- 自主迭代:以 Agent 替代人工自动解决 Bad Case