
表设计及测试
1. 需求
项目需要存储对接的第三方接口数据。对应每个用户每天会产生50个分类的日、周、月、年三种统计,也就是每个用户每天会产生200条记录。如果是1w用户的话,那么每天就是150w条
项目原表如下,已经过脱敏处理:
create table record
(
id bigint auto_increment primary key,
user_id varchar(100) not null comment '用户id',
type varchar(30) not null comment '分类的标签',
cycle int(8) not null comment '统计周期日、周、月',
value int(8) not null comment '统计值',
-- 其他字段(创建、修改时间等)
)
在上述结构中:
- type:即50个分类,会有50个不重复的标签
- cycle:即日、周、月、年的统计,其中1代表日,2代表周,3代表月,4代表年
- value:统计值,范围是(0-9),即表示:“某人某天在某个分类上的统计值”
2. 优化
我们的项目组之前是接触不到这么大的数据的,隔壁的项目组经理总是说500w就是上限,虽然在我的认知上远远不止如此,但毕竟talk is cheap
对于原来的表结构,如果是1w用户的话,每天会在数据库中插入150w的数据,以先前部门的经验来说表超过500万速度就很慢了(这里其实并不是绝对的,后面的测试环节有提及)
这里我提出的优化方法是将type、cycle和value压缩成矩阵:
create table record
(
id bigint auto_increment primary key,
user_id varchar(100) not null comment '用户id',
data char(200) not null comment '每日统计'
-- 其他字段(创建、修改时间等)
)
比如说,原表某用户某天的150条数据如下(省略了id和user_id):
(type, cycle, value)
(分类1 , 1 , 2 )
(分类2 , 2 , 4 )
(分类3 , 3 , 1 )
(分类3 , 4 , 8 )
...
(分类50, 1 , 3 )
(分类50, 2 , 2 )
(分类50, 3 , 8 )
(分类50, 4 , 7 )
在新的表中存储如下:
(data)
(2418...3287)
其中分类i的日、周、月、年统计值分别在data的(i-1)*4+1、(i-1)*4+2、(i-1)*4+3、(i-1)*4+4位
这样不但让记录的总数缩小了200倍;而且在单行的字节上,即使额外添加一些字段也不会超过0.5kb
3. 测试
那么,对于这样的结构,mysql的表究竟能存储到多少才导致性能下降呢?
为了考虑到未来可能出现的更多的冗余数据,所以这里的数据量以单条1kb测试
-- 测试环境
-- CentOS 7、32G、24核、x86
-- MySQL 8.0.33 Docker部署 默认配置
-- 创建表如下
create table record(
id bigint not null auto_increment primary key ,
tenant_id bigint,
user_id bigint,
data char(200),
test_1 char(200),
test_2 char(200),
test_3 char(200),
create_time datetime,
update_time datetime
);
这里直接给测试的冗余字段用的char(因为varchar没有实际插入的话,还是不会占空间的),分别测试了:
- count:
select count(1) from record; - 主键索引查询:
select count(1) from record where id = 'xxxxxxx'; - 全表遍历:
select count(1) from record where record.data = 'xxxxxx';, 这里record.data不是索引,所以会触发全表遍历 - 单条末尾插入
理论预估存储性能瓶颈:
- 非叶子节点存储索引约1280条
- 叶子节点存储数据页16KB,去除页目录等数据1KB,实际能存储15行
- 若三层B+树即:(1280)^2*15=24576000,即约24.5M
执行时间(ms)结果如下:
| 数据量(M) | count | 主键索引查询 | 全表遍历 | 单条末尾插入 |
|---|---|---|---|---|
| 1 | 1178 | 153 | 2595 | 221 |
| 2 | 2007 | 135 | 4652 | 178 |
| 3 | 2875 | 113 | 6892 | 189 |
| 4 | 3749 | 100 | 8637 | 208 |
| 5 | 4467 | 123 | 11424 | 128 |
| 7 | 6143 | 107 | 15125 | 135 |
| 9 | 8373 | 112 | 20074 | 145 |
| 12 | 10689 | 137 | 25010 | 159 |
| 14 | 12824 | 96 | 32317 | 167 |
| 16 | 14358 | 133 | 34445 | 139 |
| 19 | 18417 | 144 | 43603 | 149 |
| 22 | 20128 | 123 | 48467 | 155 |
| 25 | 23010 | 145 | 55727 | 141 |
| 30 | 48831 | 152 | 88283 | 156 |
| 35 | 101735 | 166 | 129489 | 163 |
这里主要的性能差距在count和全表遍历上,对其画图如下:
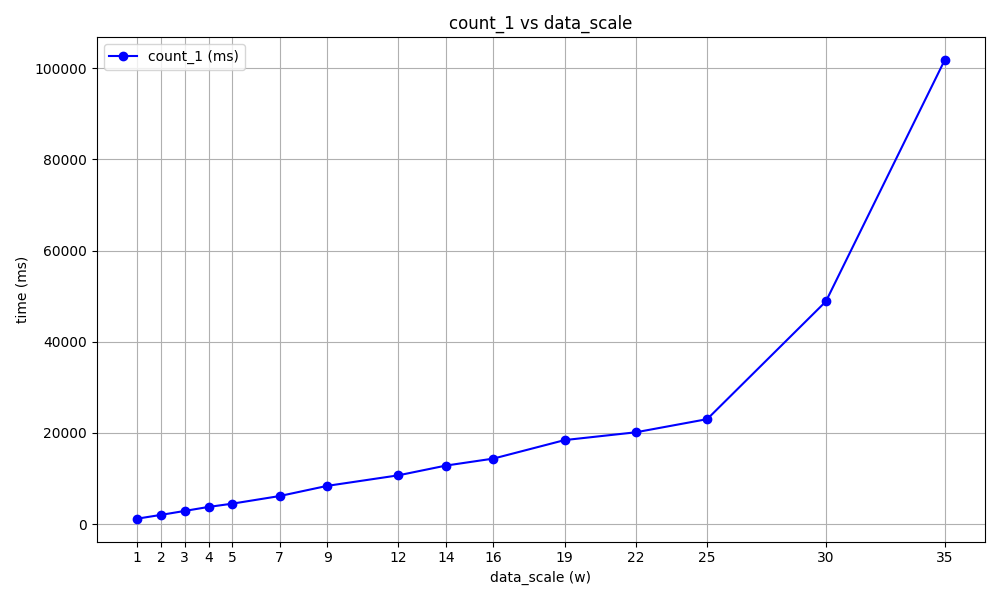

可以看出在超过25M时,数据库的性能确实受到了较大影响,但在25M以下的时候,仍然是随着数据的增长而线性增长的。
4. 性能下降的原因
- B+树从3层索引变为4层索引
当B+树从3层变成4层时,理论上是会影响索引的效率,从原来的3次索引IO变成了4次索引IO,最后再进行一次页内查找。但我觉得没道理会影响到count和全表遍历的效率
- Buffer Pool导致内存不足
MySQL会将查找的数据缓存到Buffer Pool中,也就是从磁盘IO变成了内存读取。如果内存空间不足以继续缓存数据的话,则会导致后续的查找都会去磁盘中进行IO,进而降低速度。
这里发现MySQL已经将内存的buff/cache全部吃满了,所以导致了效率的降低
# docker stats
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
c34923bad950 mysql 0.83% 14.1GiB / 31.26GiB 45.11% 78.6kB / 1.38MB 162GB / 82.3GB 44
# free -h
total used free shared buff/cache available
Mem: 31G 3.7G 202M 85M 27G 27G
Swap: 15G 295M 15G
最后的话,我认为如果支撑MySQL的内存条足够大,是可以进一步提升数据量的。当然,这属于是力大飞砖了。还是该分库分库,该Redis缓存就缓存吧。