
Java集合
1. 集合类型
Java中的主要包括 Collection 和 Map 两种,Collection 存储着对象的集合,而 Map 存储着键值对(两个对象)的映射表
- Collection
- List
- ArrayList:动态数组
- Vector:线程安全版ArrayList
- LinkedList:双向链表
- Queue
- LinkedList:双向链表
- PriorityQueue:堆
- Set
- TreeSet:红黑树
- HashSet:哈希表
- LinkedHashSet:双向链表
- List
- Map
- HashMap:哈希表
- TreeMap:红黑树
- LinkedHashMap:双向链表
- HashTable:线程安全的HashMap(目前用使用了分段锁的效率更高的ConcurrentHashMap)
2. List
2.1 ArrayList
2.1.1 底层数据结构
ArrayList底层数据结构即为数组
// 数组存放元素
transient Object[] elementData;
// 数组大小
private int size;
2.1.2 自动扩容
在ArrayList剩余空间不足容纳新元素时,会自动触发ensureCapacity(int minCapacity)来对数组进行扩容。每次触发会将新开辟一个原来1.5倍长度的数组,并将老数组的元素全部拷贝过去。
实际过程中应合理设计空间大小,避免数组扩容,或提前手动调用
ensureCapacity扩容
2.2 Vector
Vector相当于是线程安全版的ArrayList,其内部的方法都加了synchronized
2.3 LinkedList
2.3.1 底层数据结构
LinkedList同时实现了List和Deque接口,所以同时具有顺序和双端操作的特性,可以用来完成队列、栈、链表的操作
// 大小
transient int size = 0;
// 头节点
transient Node<E> first;
// 尾节点
transient Node<E> last;
同时,其内部的每一个节点也分别有头、尾两个引用
private static class Node<E> {
E item;
// 下一个
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
同时,这里也有一些有趣的优化,比如说索引的时候,先判断了在前半部分还是后半部分然后再去遍历,并且使用的是位运算size >> 1效率更高
Node<E> node(int index) {
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
3. Queue
3.1 Stack & Queue & Deque
- Stack(栈)是一个类,但是实际上使用栈的时候,Java推荐用更高效的ArrayDeque
- Queue(队列)是一个接口,继承自Collection,在使用的时候也是首选ArrayDeque了(次选是LinkedList)
- Deque(双端队列)是一个接口,继承自Queue,添加了双向的操作,因此既可以当作栈也可以当作队列
3.1.1 ArrayDeque
ArrayDeque和LinkedList是Deque的两个实现类,官方更推荐使用ArrayDeque
为了满足数组两端的插入、删除操作,解决前端操作导致数组的整体移位问题,ArrayDeque使用了循环数组(circular array)。ArrayDeque是非线程安全的,此外也不允许放入null。
3.1.2 ArrayDeque的越界处理
public void addLast(E e) {
if (e == null)//不允许放入null
throw new NullPointerException();
elements[tail] = e;//赋值
if ( (tail = (tail + 1) & (elements.length - 1)) == head)//下标越界处理
doubleCapacity();//扩容
}
这里的&非常有趣,可以快速的将左侧或右侧越界的下标匹配,比如当前的总长是8
- 当左侧需要的下一个是
-1时,会变成-1 & 7 = 7,跳到最后一个位置; - 当右侧需要的下一个时
8时,会变成8 & 7 = 0,跳到第一个位置
3.1.3 ArrayDeque的扩容机制
和ArrayList一样,基于数组的ArrayDeque也有一套自己的扩容机制,会自动扩充为原数组的两倍大,并复制原数组过去,并且首先会将head右侧到数组结尾的部分复制过去,再复制左侧的
# 比如此时head是1所在的index
[5, 6, 7, 8, 1, 2, 3, 4]
# 新开辟数组大小16, 先复制head右侧的
[1, 2, 3, 4, ...]
# 再复制左侧的
[1, 2, 3, 4, 5, 6, 7, 8, ...]
3.2 PriorityQueue
优先队列可以按照元素的权重顺序弹出,Java中的优先队列通过完全二叉树实现的小顶堆,因为是完全二叉树,所以叶子节点对应的index是可以映射到数组中的,所以PriorityQueue可以用数组来实现:
left = parent * 2 + 1right = parent * 2 + 2parent = (current - 1) / 2
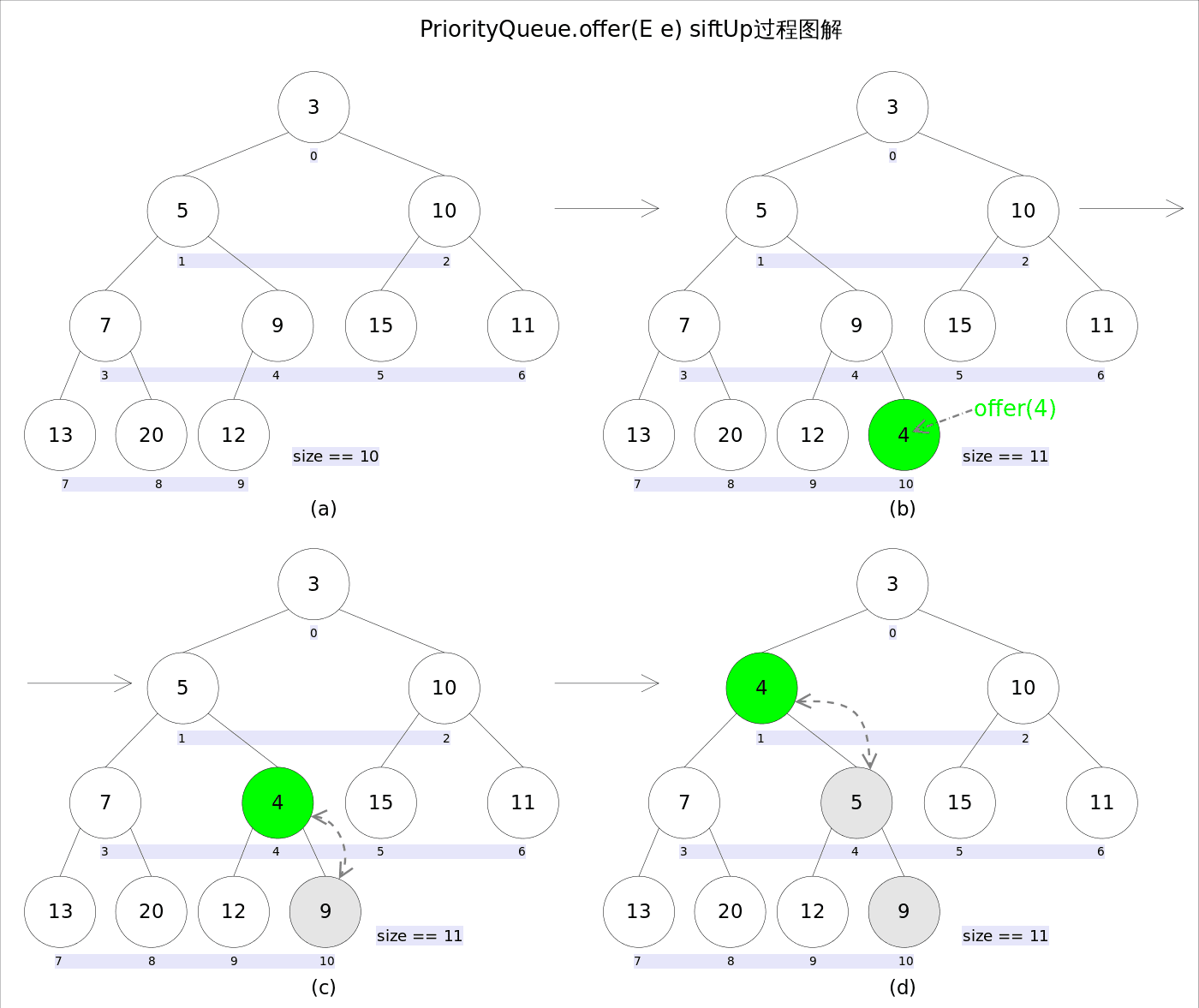
3.2.1 推入元素
小顶堆因为要维护其结构,所以在推出或推入堆顶的元素时,需要对其进行重新调整,首先看一下推入的代码:
//offer(E e)
public boolean offer(E e) {
if (e == null)//不允许放入null元素
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length)
grow(i + 1);//自动扩容
size = i + 1;
if (i == 0)//队列原来为空,这是插入的第一个元素
queue[0] = e;
else
siftUp(i, e);//调整
return true;
}
//siftUp()
private void siftUp(int k, E x) {
while (k > 0) {
int parent = (k - 1) >>> 1;//parentNo = (nodeNo-1)/2
Object e = queue[parent];
if (comparator.compare(x, (E) e) >= 0)//调用比较器的比较方法
break;
queue[k] = e;
k = parent;
}
queue[k] = x;
}
- 首先将元素放到当前的最后一个位置,并触发
siftUp从当前位置开始向上调整 siftUp与父节点进行比较,如果父节点更大则两者交换- 不断进行步骤
2,直到比父节点小或者到达顶部
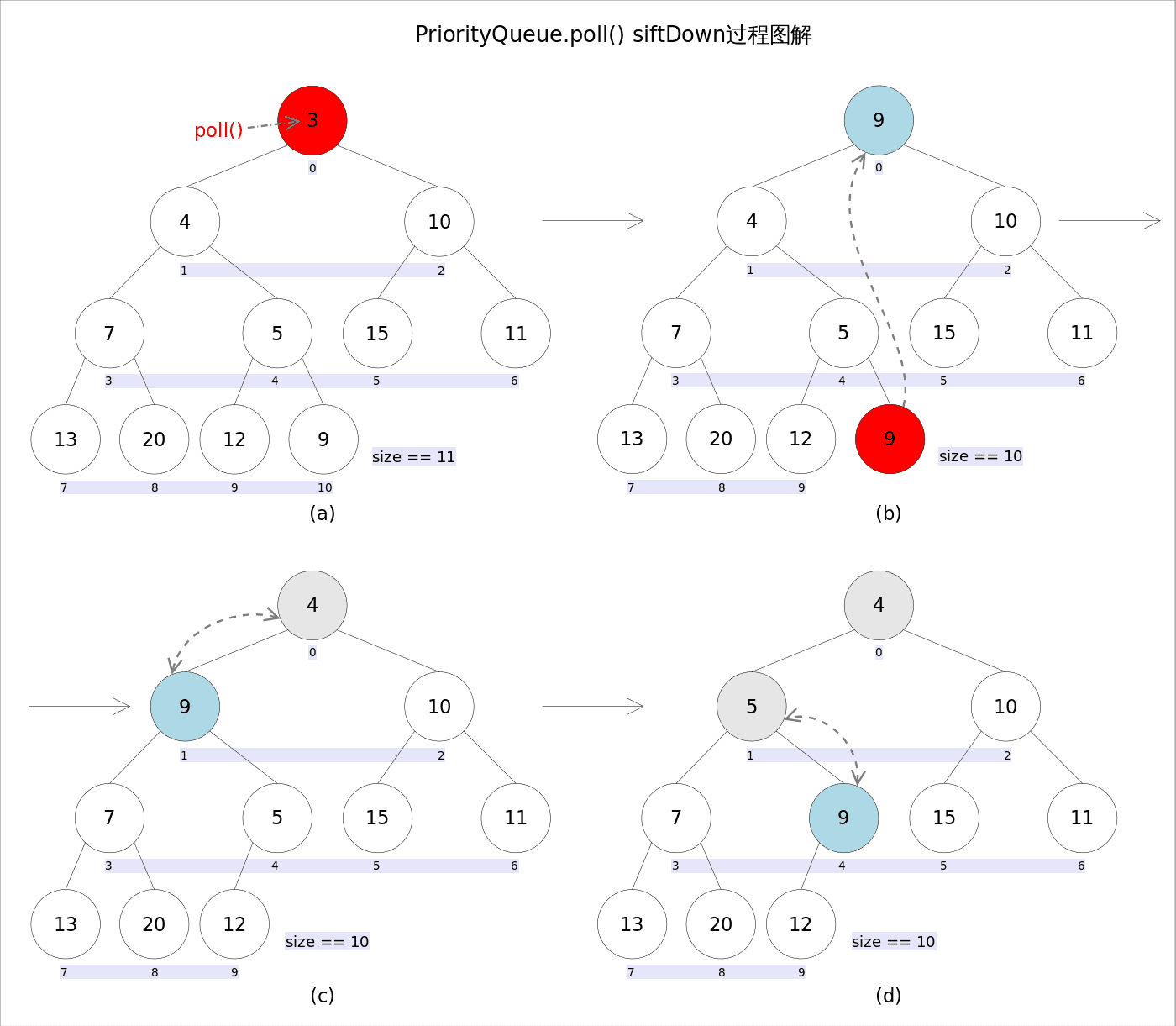
3.2.2 推出元素
然后时推出元素的
public E poll() {
if (size == 0)
return null;
int s = --size;
modCount++;
E result = (E) queue[0];//0下标处的那个元素就是最小的那个
E x = (E) queue[s];
queue[s] = null;
if (s != 0)
siftDown(0, x);//调整
return result;
}
//siftDown()
private void siftDown(int k, E x) {
int half = size >>> 1;
while (k < half) {
//首先找到左右孩子中较小的那个,记录到c里,并用child记录其下标
int child = (k << 1) + 1;//leftNo = parentNo*2+1
Object c = queue[child];
int right = child + 1;
if (right < size &&
comparator.compare((E) c, (E) queue[right]) > 0)
c = queue[child = right];
if (comparator.compare(x, (E) c) <= 0)
break;
queue[k] = c;//然后用c取代原来的值
k = child;
}
queue[k] = x;
}
- 首先推出顶部元素,并用最后的元素替代顶部元素
- 找到顶部元素的左右更小的节点并交换
- 不断重复步骤
2,直到左右节点都比自身小或者到达最后一行(这里最开始就用half = size >>>1计算了非叶子节点的最后一个位置
4. Set
java中的Set都是以适配器模式封装的Map,底层实现相同
4.1 HashSet
Java中的HashSet和HashMap具有相同的实现,HashSet内部包含了HashMap(适配器模式),将一些方法包装后调用内部的HashMap方法(将Key-Value的Value替换为Object)
4.2 TreeSet
Java中的TreeSet和TreeMap具有相同的实现,TreeSet内部包含了TreeMap(适配器模式),将一些方法包装后调用内部的HashMap方法(将Key-Value的Value替换为Object)
4.3 LinkedHashSet
Java中的LinkedHash和LinkedHashMap具有相同的实现,LinkedHashSet内部包含了LinkedHashMap(适配器模式),将一些方法包装后调用内部的LinkedHashMap方法(将Key-Value的Value替换为Object)
5. Map
5.1 HashMap
5.1.1 冲突机制
HashMap实现了Map接口,其底层结构将数组用作哈希槽,将链表用作冲突处理,是非线程安全的数据结构
在冲突处理方面,有两种方法:
- 开放地址方式:也就是一直在同一个哈希槽上Hash,直到找到一个空位为止
- 冲突链表方式:将哈希槽的index对应一个链表,在链表上实际存储值,冲突了就插入链表头
5.1.1 扩容机制
1. 扩容因子
- 扩容因子指的是当前HashMap中的元素总数占哈希槽的比例,Java中设置为
0.75 - 如果达到了
0.75则会触发双倍空间的数组扩容,并重新计算哈希,此时因子会掉落到0.375,因此平均的因子为0.5625
2. 链表转红黑树
- 在单个index的节点上,在Java8之前使用的是单纯的链表,这样查找的效率是
O(N) - Java8之后将这一部分优化为了红黑树实现,当链表达到
8的时候会转换为红黑树,效率变为O(logN)
HashMap的平均容量为0.5625,在这种情况下,0.5625^8 = 0.01,所以出现8个冲突的概率极低
5.2 TreeMap
TreeMap实现了SortedMap接口,按照key的大小对Map中的元素进行了排序,底层通过红黑树实现,是非线程安全的数据结构
关于红黑树相关:红黑树
5.3 LinkedHashMap
相比HashMap,LinkedHashMap将所有的元素根据先后插入的顺序,维护在了一个LinkedList上,是非线程安全的数据结构,具有以下特点:
- 为了维护LinkedList的前后插入关系,这里并没有链表转红黑树的操作
- 整体遍历更快,LinkedHashMap可以只迭代LinkedList,而无需迭代所有的哈希槽
- 在插入时,要同时插入冲突链表的头部和双向链表的尾部
LinkedHashMap维护了插入的先后顺序,所以可以用来维护一个容量大小固定的FIFO容器,比如在新的元素插入的时候,可以弹出最早插入的元素